✏️ 본 포스트에는 논문 및 여타 개념에 대한 주관적 해석 및 설명이 포함되어 있습니다. 출처를 표시하지 않은 경우 모두 개인의 이해를 바탕으로 작성되었기 때문에, 공식적인 용도로 내용을 차용해가시는 것에 주의하시길 바랍니다! 그 외에 이해한 바에 대한 공유, 댓글을 통한 디스커션 모두 환영합니다 :)
이 논문은 학회 포스터 세션의 재미를 제일 먼저 느낄 수 있었던 아이다!
Northeastern University, Google Cloud AI, Google Research에서 작업한 논문이었다. *_*
논문 링크 (CVPR, arXiv) | 깃헙



지난 학기에 교수님을 통해 추천 받았던 논문 중 "Visual Prompting"이라는 논문이 있었다. (참고로 이 논문도 얼마 전에 깃헙 레포지토리를 공개해주셨다. 업데이트된 논문 제목은 "Exploring Visual Prompt for Adapting Large-Scale Models"이다. 한국인 저자 분이시고 동문이어서 너무 반가웠던!! 아직 학회에 퍼블리쉬되지는 않은 것 같다. 논문 링크, 깃헙, 프로젝트 페이지.)
(Preliminary) Prompt
두 논문에서 등장하는 핵심 개념인 'prompt'는 원래 NLP 분야에서 주로 등장하는 개념이다. 많은 양의 데이터로 Pre-train된 large-scale 모델을 downstream task로 전이학습(Transfer learning)을 할 때 많이 사용되는 기법이다.
일반적으로 Transfer Learning을 할 때, 가장 쉽게 생각할 수 있는 방법이 Pre-trained 모델을 내가 원하는 Downstream task에 대해 다시 학습을 시키는 것일 거다. 이미 많은 데이터로부터 학습된 "똑똑한" 모델이기 때문에, Downstream task에 대해 바닥부터 학습을 시킬 때보다 좀더 수월하게 Optimize할 수 있다는 장점이 있다.
여기서 Prompt를 사용하면 그 똑똑한 Pre-trained 모델을 추가로 업데이트하지도 않고 내가 원하는 task에서 성능을 내게 할 수 있다. 어떻게 하느냐, 내가 원하는 (downstream) task를 Pre-train 할 때의 task의 모양에 맞춰주는 거다. 즉, Pre-trained 모델은 본인이 하던 것만 잘 하면 되는 것이고, 나는 내가 원하는 task에 대해 똑똑한 모델의 능력을 그대로 활용할 수 있는 거다.
예를 들어, 아래의 경우를 생각해보자.

Language Modeling으로 학습된 Pre-trained 모델을 가지고 Sentiment Classification을 수행하고 싶다고 하자. Sentiment Classification은 문장이 주어졌을 때, 긍정인지 부정인지 분류하는 태스크일 것이다. 지도학습 방식으로 긍/부정을 Label로 삼아 문장(X), sentiment(y) 의 형태를 학습할 것이다.
이걸 Prompt를 사용한 방식으로 바꾸면,

이렇게 Language modeling 태스크의 형식으로 템플릿을 만들어주는 거다.
위의 경우, 분류하고 싶은 문장 뒤로 "It was"를 붙여주고 그 뒤의 단어로 great(긍정)/terrible(부정)을 예측하게 하고 있다. Language modeling task가 주로 문장의 중간에 masked된 단어 혹은 다음에 올 단어를 예측하는 태스크이기 때문에, Sentiment Classification 태스크를 이런 식으로 바꿔주면 Language modeling으로 학습된 Pre-trained 모델이 좀더 편하게 일할 수 있는 거다.
따라서, 넓게 생각하면 이렇게 태스크와 관련된 힌트를 줄 수 있는 방향으로 모델의 Input에 변형을 가해주는 걸 Prompting이라고 생각할 수 있다.
Learning to Prompt for Continual Learning
저자들이 논문에 제시한 contribution도 있겠지만, 개인적으로 의미 있다고 생각하는 바는 다음과 같다.
- NLP에서 자주 사용되는 Prompt의 개념을 컴퓨터비전 분야에 가져왔다는 점,
- 인코더를 fix해둔 채로 task가 추가될 때마다 prompt에 대한 업데이트만 이루어지기 때문에, 덩치가 큰 Pre-trained 모델의 파라미터를 업데이트 시킬 필요가 없다는 점 (업데이트할 parameter 수가 줄어드니 memory efficient!)
- task-specific한 성격을 띠는 prompt를, task id가 없는 CL 세팅으로 구현할 수 있게 prompt pool의 개념을 가져온 점!
task id가 필요 없다는 점이나, buffer에 rehearsal data를 저장할 필요가 없다는 점 등은 다른 많은 CL(Continual Learning) method에서도 가능하게 했지만, 그걸 prompt를 접목해 풀어낸 게 재미있었다.
앞서 말했듯, 전에 visual prompting의 개념을 보고 이렇게 transfer하는 방식을 CL에 어떻게 접목할 수 있을지 고민했던 적이 있다. 그 논문에서는 input에 직접 픽셀 단위의 prompt를 더해주는 방식이었는데, 이걸 뒤이어지는 session에서 각기 다르게 학습한다면 inference할 때 어떤 prompt를 써야할 지 애매해지기 때문이다. 그리고 매 session마다 prompt를 학습시킨다면 session이 무한정 늘어나는 상황을 고려해도 문제가 있었고. 아무튼 그런 개인적인 경험 때문에 더 재미있게 본 것 같다!

Training Process
위의 메인 피겨에서, training이 이루어지는 방식은 다음과 같다.
- Input 이미지가 들어오면
- Query function을 통해 임베딩 벡터의 형태로 input query가 만들어진다.
- Prompt pool에서 input query와 가장 가까운 몇 개의 prompt를 선정한다. ("Matched pairs")
- 고정된 Pretrained Embedding Layer를 지난 input의 embedding들 앞에, 선정된 prompt들을 이어붙여준다. ("Prepend selected prompts")
(인코더로 ViT(트랜스포머)를 사용하기 때문에, input 이미지를 패치로 나눠 토큰화하고 각 패치에 대한 임베딩 벡터의 시퀀스가 만들어지게 된다. CNN이 아닌 ViT를 사용해서 Prompt를 갖다 붙이기 더 편했을 것 같다!) - Prompt가 결합된 형태로 Pretrained Transformer Encoder에 입력된 뒤 classifier를 지나 분류를 수행한다.
👉 여기에서 계산되는 Loss를 통해 Prompt pool과 classifier를 학습시키게 된다. (Pretrained된 모듈들은 모두 고정되어 업데이트되지 않음)
실험 세팅이 Class-incremental 세팅이라면, 이렇게 prompt pool을 한 번 학습시킨 뒤에 새로운 클래스들이 들어올 때 다시 업데이트해주는 게 필요하다. 이 때도 마찬가지의 방식으로 prompt pool에 대한 업데이트가 이루어지며, classifier는 추가되는 클래스에 대한 유닛만 학습된다. (논문에서는 Class-incremental Setting과 Domain-incremental Setting에 대해 모두 실험한 결과를 보여준다.)
Loss (Objective)
이 업데이트를 위해 사용되는 objective function은 다음과 같다.
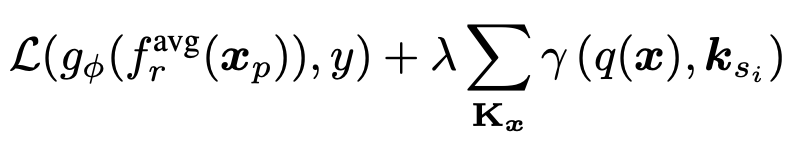
앞의 항은 Cross entropy Loss이다. 단순히 classification 결과에 대한 loss라고 생각하면 된다.
두번째 항이 prompt pool과 관련된 loss인데, query function을 지난 벡터와 선정된 prompt들 간의 거리를 좁혀주는 역할을 한다. 즉, 아래 표시된 부분의 거리를 좁혀주는 거다.

이렇게 하면 prompt pool의 prompt들이 분류에 도움이 되는 방향으로 task-specific한 성격을 띠게 구성되는 것에 도움을 줄 것이다.
(참고로 prompt pool에서 각 prompt가 어떤 걸 대변하는 건지, 어떤 정보를 주는 건지에 대해 감이 잘 안 왔는데, classification task에 대해 학습하기 때문에 기본적으로 각 class를 분류하기 좋은 정보를 가지고 있다고 생각할 수 있을 것 같다. class와 관련된 정보로 받아들이면 될 듯..!)
L2P - Continual Learning
'prompt가 업데이트되면 결국 앞선 task에 대해 잊어버리는 건 피할 수 없지 않을까' 하는 생각을 할 수 있지만, prompt를 거리 기반으로 선택하고 업데이트하기 때문에 유사한 태스크에 대해서는 유사한 prompt 구성을 적당히 유지할 수 있게 된다. 물론 forgetting을 완전히 막아주지는 않는다. 하지만 이전 task의 정보를 활용해 새로운 task를 위한 prompt를 구성한다는 점에서 효율적으로 이전 정보에 대해 유지해간다고 볼 수 있을 듯하다.
Continual Learning 테크닉들을 보면, stability-plasticity 의 균형을 맞추기 위한 장치로 이루어져 있다. 어떻게 보면 당연한 얘기다.
Stability는 얼마나 기존 정보를 잘 기억하는지에 대한 성질이고, Plasticity는 얼마나 새로운 task에 잘 적응하는지에 대한 것, 즉 Adaptation을 위한 성질이다. Stability가 극단적으로 보존되는 경우는 아예 모델의 업데이트가 이루어지지 않고 첫번째 task에 대한 기억만 가지고 있는 걸 생각해볼 수 있다. 반대로 Plasticity가 극단적으로 보장되는 상황은 단순히 모델을 계속 fine-tuning하는 경우일 것이다. 이 둘은 당연하게도 trade-off / 딜레마 관계에 있다. 물론 다 잘하면 베스트지만!
이 L2P의 구조 역시 Stability 와 Plasticity를 담당하는 부분으로 해석해보자면, 새로운 task에 대한 적응을 담당하는 부분이 prompt pool이고, Stability를 담당하는 부분이 Pre-train된 인코더 모듈들이라고 생각할 수 있다. Prompt pool은 우선 새로운 task가 추가될 때 직접적으로 업데이트 되는 부분이고, Pre-trained 모델은 다량의 데이터로 이미 학습이 되어 있어 Generalization ability가 어느 정도 보장되기 때문에, task가 계속 추가될 때도 성능을 전체적인 task에 대해 유지해주는 역할을 할 수 있기 때문이다.
Prompt pool로 classification task에 대한 정보를 업데이트해가는 게 또 의미가 있을 것 같은 건, 이전 class들과 현재 class들 간의 관계(Semantic Relation)를 담고 있을 것이기 때문이다. 이전 task에서 학습된 class들이, 이후 task에서 그 관계를 바탕으로 다시 뭉치고 업데이트되기 때문에 서로 다른 task에서 주어지는 클래스들 간의 상호작용이 어느 정도 이루어진다고 생각할 수 있다.
이 논문은 메인 컨퍼런스에서 처음으로 구경한 포스터였고, 주변에 사람이 우글우글 굉장히 많아서 중간에 어떤 분이 지나가면서 '포스터를 볼 수 있게 좀 떨어져서 서달라'고 사람들에게 요청까지 했다. 거의 저자 옆으로 붙어서 포스터를 다 가리고 서있었다. ㅋㅋㅋ
사람들이 질문도 많이 하고 저자도 설명을 열심히 해줘서, 옆에서 주워들으며 이해하는 데에 많이 도움이 됐다.
내가 궁금했던 건, Prompt pool의 prompt의 개수가 어떻게 되는지, prompt의 개수에 제한을 둬야 한다면 문제가 되는 경우는 없는지, session이 추가될 때 classifier는 정확히 어떻게 학습되는 건지, 등 내 머릿속에서 정확히 그려지지 않은 부분들이었다.
Prompt pool의 개수는 어떤 분이 질문을 해주셔서 저자가 답을 해주었고 (참고로 논문에도 당연히 언급되어 있었다! 30개 정도를 사용한 걸로 기억한다.), 그에 뒤이은 Scalability에 대한 질문에는 끄덕끄덕하며 한계가 있다는 듯 반응했다. 비슷한 task, 즉 비슷한 수준의 class가 추가되는 건 크게 문제가 없을텐데, 완전히 다른 결의 class가 많이 추가된다든지 하는 상황에서는 prompt pool의 확장성에 대해 고민해볼 필요가 있다는 느낌이었다.
나는 수많은 사람들 앞에서 저자에게 그냥 '나의 이해를 도와주세요' 할 자신이 없어서 사람이 좀 줄어들길 기다리며 몇 번이나 왔다갔다 했는데, 계속 사람이 많았다.. 완전 인기 짱이었음..
그러다, 알고보니 옆에 서있던 분이 구경하러 오신 분인 줄 알았는데 저자 분이셨어서 그 분께 조용히 가서 질문을 했다. 그 분과 linkedIn 일촌도 맺었다! ㅎㅎ 엄청 잘 설명해주셨다. 나도 멋진 논문 쓰고 완전 친절하게 설명해주고 싶다.....ㅇ.ㅇ 멋졌다..!
포스터 세션에서 질문들을 들으며 느낀 바가 꽤 많았다. 특히 prompt 의 개수에 대해 궁금했던 것과 관련해, 질문을 할 법도 한데 계속 듣고만 있다가, 누군가 그 질문을 했을 때 '아 내가 가지는 질문이 생뚱맞지만은 않구나! 나도 궁금할 만한 게 궁금한거구나' 하는 안도감이 들었고, 또 그와 관련해 Scalability에 대한 질문을 들었을 때는, 나는 단순히 prompt 개수도 제한이 있어야 할텐데 그럼 뭔가 한계가 있지 않을까... 하는 정도의 감만 있었는데 그게 task가 무한정 늘어나는 세팅에서의 scalability의 문제로 명확하게 제시되는 걸 보고 '감'에서 '문제 정의'로 넘어가는 게 정말 한끗차이이고 그 차이는 내공과 경험에서 우러나오는 것 같다는 생각도 들었다. 나도 좀더 명확하게 무언가를 제시할 수 있게 열심히 해야지!!! 하는 생각!!
이상 논문리뷰 치고 간단하고도 장황한, 포스터 세션 리뷰(?) 끝!
'논문 읽기' 카테고리의 다른 글
| [CVPR2022 논문 간단 리뷰] Forward Compatible Few-Shot Class-Incremental Learning (FACT) (0) | 2022.08.09 |
|---|